
1. String的基本特性
- String : 字符串 创建方式:String str = “good” ; String str = new String(“good”)
- String 声明为final,不能被继承
- String实现了serializable接口,表示字符串是支持序列化的,实现了comparable接口表示字符串是可以比较大小的
- String在jdk8及以前内部定义了final char[] value用于存储字符串操作,jdk9改为了byte[]
jdk9 String存储结构变更

string:代表不可变的字符序列。简称:不可变性。
- 当对字符串重新赋值时,需要重写指定内存区域赋值,不能使用原有的value进行赋值
- 当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值
- 当调用String的replace()方法修改指定字符或字符串时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
通过字面量的方式(区别于new)给一个字符串赋值,此时的字符串值声明在字符串常量池中
字符串常量池中是不会存储相同内容的字符串的

2.String的内存分配
- 在java语言中有8种数据类型和一种比较特殊的数据类型String,这些类型为了使他们在运行时速度更快,更节省内存,都提供了一种常量池的概念。
- 常量池就类似于一个java系统级别提供的缓存。8种基本数据类型的常量池都是系统协调的,String类型的常量池比较特殊,他主要使用的方法有两种。
- 直接使用双引号声明出来的string对象会直接存储在常量池中,比如 String str = “zhangjunyan”
- 如果不是用双引号声明的String对象,可以使用string提供的intern()方法
String Table位置调整
- Java 6及以前,字符串常量池存放在永久代
- java7中oracle的工程师对字符串池的逻辑做了很大的改变,即将字符串常量池的位置调整到java堆内。
- 所有的字符串都保存在堆中,和其他普通对象一样,这样可以让你在进行调优应用时仅需要调整堆大小就可以了
- 字符串常量池概念原本使用的比较多,但这个改动使得我们有足够的理由让我们重新考虑在java 7 中使用string intern()
- java8元空间,字符串常量在堆
String Table为什么要调整
- PermSize默认比较小 容易OOM
- 永久代垃圾回收频率低
3.String的基本操作

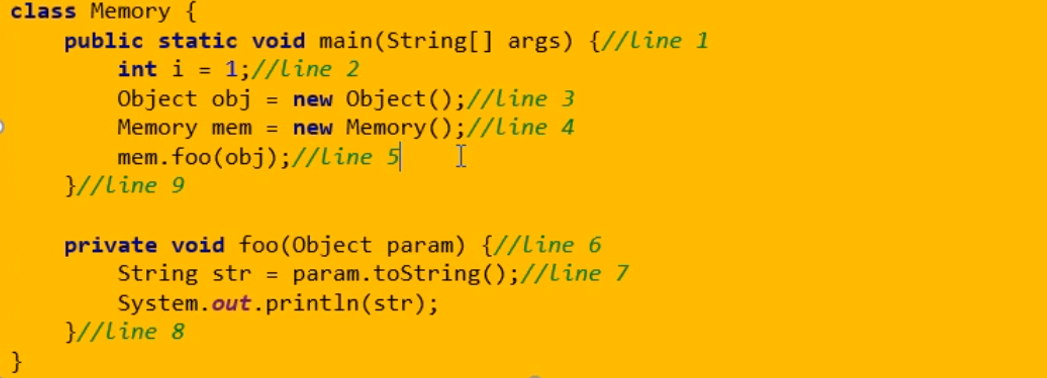

4. 字符串拼接操作
- 常量与常量的拼接结果在常量池,原理是编译期优化
1 | public void test1() { |

- 常量池中不会存在相同的常量
只要其中有一个是变量,结果就在堆中,拼接的原理是StringBuilder
1 | public void test2(){ |

1 | public void test3(){ |
1 | /* |

- 练习
1 | public void test5(){ |
- 拼接操作与append操作的效率对比
1 | /* |
- 如果拼接的结果调用intern ()方法,则主动将常量池中还没有的字符串对象放入池中,并返回此对象地址。
5. intern()的使用

1 | 如何保证变量s指向的是字符串常量池中的数据呢? |

- 面试题
1 | public class StringIntern { |


扩展(1.7以后):
1 | public static void main(String[] args) { |
总结:
- jdk1.6中,将这个字符串对象尝试放入串池。
- 如果串池中有,则并不会放入。返回已有的串池中的对象的地址。
- 如果没有,会把此
对象复制一份,放入串池,并返回串池中的对象地址。
- Jdk1.7起,将这个字符串对象尝试放入串池。
- 如果串池中有,则并不会放入。返回已有的串池中的对象的地址。
- 如果没有,则会把
对象的引用地址复制一份,放入串池,并返回串池中的引用地址。
6.StringTable的垃圾回收
1 | /** |
1 | [GC (Allocation Failure) [PSYoungGen: 4096K->488K(4608K)] 4096K->712K(15872K), 0.0015257 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] |
7.G1中的String去重操作
- 背景:对许多Java应用(有大的也有小的)做的测试得出以下结果:
- 堆存活数据集合里面string对象占了25%
- 堆存活数据集合里面重复的string对象有13.5%
- string对象的平均长度是45
- 许多大规模的Java应用的瓶颈在于内存,测试表明,在这些类型的应用里面,Java堆中存活的数据集合差不多25%是string对象。更进一步,这里面差不多一半string对象是重复的,重复的意思是说:stringl.equals (string2 )=true。堆上存在重复的string对象必然是一种内存的浪费。这个项目将在G1垃圾收集器中实现自动持续对重复的string对象进行去重,这样就能避免浪费内存。
- 实现
- 当垃圾收集器工作的时候,会访问堆上存活的对象。对每一个访问的对象都会检查是否是候选的要去重的string对象。
- 如果是,把这个对象的一个引用插入到队列中等待后续的处理。一个去重的线程在后台运行,处理这个队列。处理队列的一个元素意味着从队列删除这个元素,然后尝试去重它引用的string对象。
- 使用一个hashtable来记录所有的被string对象使用的不重复的char数组。当去重的时候,会查这个hashtable,来看堆上是否已经存在一个一模一样的char数组。
- 如果存在,String对象会被调整引用那个数组,释放对原来的数组的引用,最终会被垃圾收集器回收掉。
- 如果查找失败,char数组会被插入到hashtable,这样以后的时候就可以共享这个数组了。
- 命令行选项
- UsestringDeduplication (bool):开启string去重,默认是不开启的,需要手动开启。
- PrintstringDeduplicationstatistics (bool):打印详细的去重统计信息。
- stringDeduplicationAgeThreshold (uintx):达到这个年龄的string对象被认为是去重的候选对象。

